


12
May
Scale automated trading on MT4/MT5: a complete guide
TL;DR:
- Operational scaling of automated trading systems requires reliable infrastructure with adequate resources and proper isolation to prevent cascading failures. Traders must implement automated risk controls, thorough strategy validation, and real execution testing to ensure consistent live performance. Focusing on resilience and monitoring infrastructure health often yields higher returns than strategy optimization alone.
You’ve built a profitable expert advisor, backtests look great, and now you’re ready to scale across multiple accounts or terminals. Then reality hits: a VPS reboot wipes three positions, a parameter tweak that worked perfectly in backtesting fails live, or a single terminal crash cascades into a risk-limit breach across your entire portfolio. Operational scaling is a first-order problem that most traders underestimate, treating infrastructure and monitoring as afterthoughts rather than core components of the trading system itself.
Table of Contents
- Prepare your trading environment for scale
- Optimize strategies and avoid overfitting
- Implement automated risk management and fail-safes
- Test real execution and monitor performance at scale
- What most traders miss about scaling automated systems
- Ready to automate and scale smarter?
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Plan infrastructure first | Allocating resources and isolating accounts prevents performance drops and cascading failures. |
| Validate strategies robustly | Walk-forward testing and out-of-sample checks reduce the risk of live performance gaps. |
| Automate risk controls | Automated loss limits and kill switches are critical for safe, emotion-free scaling. |
| Benchmark live execution | Regularly monitor real slippage, fills, and execution times against backtests to ensure real-world success. |
Prepare your trading environment for scale
Before you add a single new terminal or increase lot sizes, your infrastructure needs to be ready. This is where most traders skip ahead too quickly, assuming their current VPS or local machine “should handle it.” That assumption gets expensive fast.
The realistic capacity of any given server depends on how many active terminals you’re running simultaneously. A standard MT4 terminal with one EA attached typically consumes around 150 to 250 MB of RAM and 5 to 15% CPU on a single core during peak market activity. Multiple MT5 terminals require dedicated CPU and RAM per instance, and skimping on resources leads to EA crashes or missed executions at exactly the wrong moment.
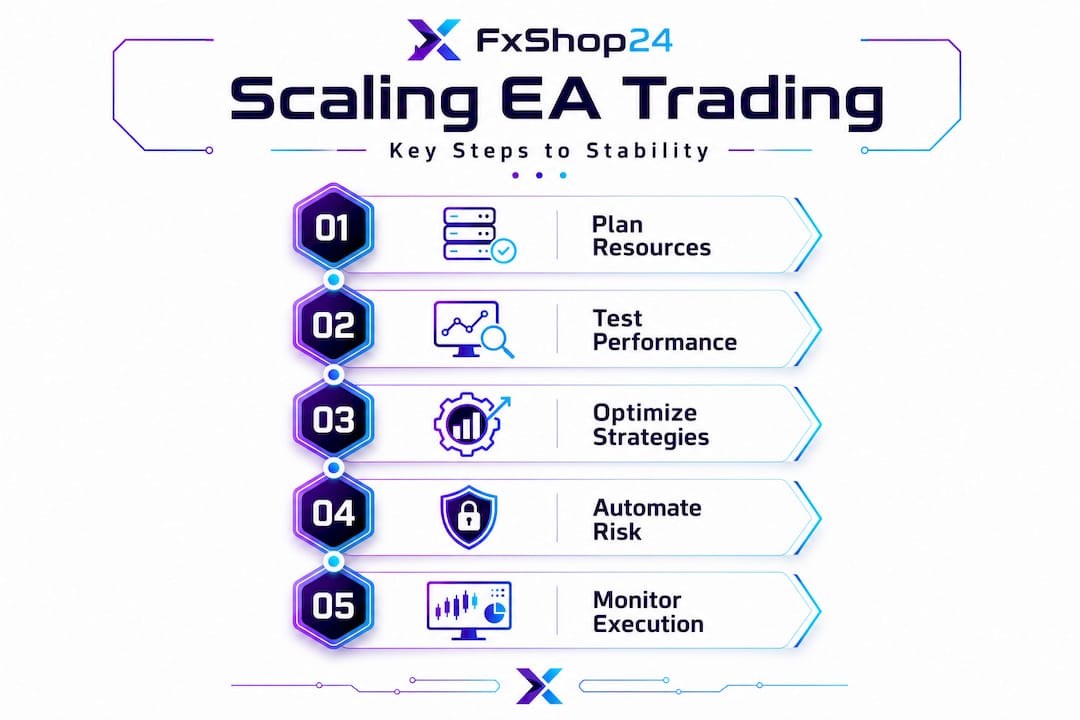
| Platform instance | Recommended RAM | CPU cores | Notes |
|---|---|---|---|
| 1x MT4 terminal | 512 MB | 0.5 core | Light load, 1 to 3 EAs |
| 1x MT5 terminal | 768 MB to 1 GB | 1 core | More resource-intensive |
| 4x MT4 terminals | 2.5 GB | 2 cores | Parallel execution risk |
| 4x MT5 terminals | 4 GB | 4 cores | Isolation recommended |
| 8+ mixed terminals | 8 GB+ | 6 to 8 cores | Dedicated VPS per group |
The table above assumes moderate EA complexity. High-frequency scalpers, EAs with neural network components, or strategies running on multiple symbols simultaneously will push those numbers significantly higher.
Why isolation matters so much: When multiple terminals share the same installation folder or operating system session, a crash in one can trigger memory conflicts that destabilize the others. Infrastructure reliability is a genuine scaling constraint because a single slowdown on a shared VPS can cause delayed order execution across every account simultaneously. Separate user sessions or dedicated VPS instances per strategy group are the gold standard for serious scaling.
Key red flags to watch for as you scale:
- Sudden latency spikes during high-volume news events
- Terminal freezes that require manual restarts
- EA logic running on outdated price data due to feed lag
- Network dropouts that leave pending orders unattended
- RAM usage climbing over 80% during normal trading hours
Pro Tip: Always provision at least 30% more RAM and CPU than your peak usage tests suggest. Software updates, Windows background processes, and volatility spikes during major economic releases all create resource demands you can’t fully predict in advance.
For deeper guidance on CPU and RAM planning for EAs, understanding how different automated system types consume resources differently will help you allocate capacity more accurately. Pairing that knowledge with cloud-based resource planning tools can simplify infrastructure decisions as your portfolio grows.
Optimize strategies and avoid overfitting
With your technical base covered, refine your strategies to perform reliably at scale by following robust optimization practices. This is the area where traders feel the most confident, and it’s also where the most dangerous mistakes happen quietly.
Overfitting is the silent killer of scaled EA performance. An EA that has been tuned too precisely to historical data will appear rock-solid in backtesting and completely fall apart in live conditions. The more parameters you optimize, the more likely your EA has learned the noise in historical data rather than genuine market structure. This is especially dangerous when you scale because you’re amplifying the performance of a strategy that may have been fundamentally flawed from the start.
Here is a practical checklist for validating EA robustness before committing capital at scale:
- Walk-forward analysis: Divide your historical data into rolling in-sample and out-of-sample windows. An EA that performs consistently across each walk-forward period shows genuine adaptability, not curve-fitting. MT5 optimization should focus on stable parameter regions, not the single combination that produced the highest theoretical profit.
- Parameter sensitivity testing: Shift your optimized parameters by 10 to 20% in each direction. If performance collapses with small changes, your settings are fragile and likely overfit.
- Multi-instrument and multi-timeframe validation: Test your EA on related symbols and timeframes it wasn’t optimized for. A robust strategy will show consistent logic across instruments, not just on the specific pair you tuned it for.
- Out-of-sample benchmarking: Reserve at least 20 to 30% of your historical data that was never used during optimization. Use this purely for validation, not further tuning.
Scaling decision logic adds another layer of complexity. If your EA uses pyramiding (adding to winning positions), the scaling decision logic must itself be validated with out-of-sample testing, because machine learning models that determine when to add positions are particularly prone to fitting historical drawdown patterns. A pyramiding EA that looks brilliant in backtests can rapidly amplify losses when conditions change.
Pro Tip: Always validate your EA across at least two distinctly different market regimes, for example a trending period versus a ranging period from recent history. A strategy that only survived trending markets in 2023 may not be suitable for deploying significant capital in 2026.

For a structured approach to trading algorithm optimization that reduces the risk of overfitting before you scale, understanding real-world patterns from real-world automation cases gives useful reference points for what robust performance looks like in practice.
Implement automated risk management and fail-safes
Effective scaling isn’t just about returns. It hinges on bulletproof risk controls that operate without any human intervention, especially during the moments when you most want to override them.
Here’s the uncomfortable truth: the bigger your automated operation grows, the more dangerous your emotional responses become. A trader running one account can manually stop losses. A trader running eight accounts across two VPS instances during a flash crash will make decisions under extreme stress, and those decisions are almost always wrong. Automation removes that vulnerability by enforcing rules when your judgment is at its weakest.
Risk warning: Platform failures, VPS crashes, or network outages during high-volatility events can simultaneously impact all accounts on the same infrastructure. Without automated kill switches, a single technical failure can cascade into portfolio-wide risk limit breaches before any manual intervention is possible.
Automated risk limits such as maximum daily loss thresholds and automated flattening mechanisms are the structural safeguards that make real scaling possible without discretionary risk-taking. These tools enforce consistent behavior regardless of market conditions or trader stress levels.
Follow this implementation sequence to build a reliable risk management layer:
- Set hard daily loss limits at the account level. Most prop firm risk environments require this, but retail traders should implement it regardless. Define the exact dollar or percentage threshold at which all trades on that account are closed and no new trades are allowed.
- Program kill switches into your EA or use a separate risk manager EA. This should operate independently from your strategy logic so that a frozen strategy EA doesn’t also freeze your risk controls.
- Define drawdown thresholds at the portfolio level, not just per account. If your total equity across all accounts drops by a predefined percentage, the entire operation should pause for review.
- Simulate crisis conditions during testing. Deliberately disconnect your VPS from the internet mid-trade during a demo session. Check that pending orders behave as expected and that your EA recovers gracefully on reconnection.
- Document and test every fail-safe monthly. Rules that haven’t been tested aren’t rules. They’re assumptions.
For practical guidance on building these systems, automated risk management tools specifically designed for MT4 and MT5 environments can significantly shorten implementation time.
Test real execution and monitor performance at scale
With risk and strategy validated, confirm your scaled setup delivers its promised performance through real execution testing. This step is where the theory meets reality, and where most traders get their first unpleasant surprises.
Backtests assume perfect execution: orders fill at the exact requested price, every single time. Live markets don’t work that way. The gap between your backtest equity curve and your live account performance is almost entirely explained by execution benchmarking failures, where realistic fill assumptions were never factored into the original model.
| Testing environment | Fill accuracy | Slippage modeled | Latency included | Reliability |
|---|---|---|---|---|
| Standard backtest | Ideal (100%) | Minimal or none | None | Low |
| MT5 tick-accurate backtest | High (85 to 95%) | Partial | Some | Moderate |
| Demo account simulation | Moderate (75 to 90%) | Partial | Broker-side only | Moderate |
| Live account at small size | Real fills | Real slippage | Full latency | High |
| Full-scale live operation | Real fills at volume | Volume-adjusted slippage | Infrastructure-dependent | Only benchmark |
Slippage reality check: During the high-impact news events that characterized 2024 and continued into 2025, average slippage on major forex pairs at peak execution moments ranged from 1.5 to 4 pips per trade for standard retail execution environments. On a scalping EA making 200 trades per month, that’s the difference between a winning and losing strategy.
Key execution statistics you must monitor continuously once you scale:
- Fill ratio: What percentage of orders execute at the requested price or better
- Average slippage per trade: Broken down by session (London, New York, Asian overlap)
- Latency spikes: Milliseconds between order submission and confirmation during news events
- Rejection rate: How often limit or stop orders are rejected rather than filled
Align your monitoring to real infrastructure scale. Testing on one terminal in demo mode does not replicate what happens when eight terminals submit orders simultaneously during a non-farm payroll release.
For documented examples of how different configurations perform in live conditions, reviewing trading strategy examples gives context for setting realistic performance expectations across your scaled operation.
What most traders miss about scaling automated systems
Most guides on scaling EAs treat it as a strategy problem. Optimize better, tune parameters more carefully, and the results will follow. That framing is wrong, and it costs traders real money.
The traders who successfully scale their automated systems almost universally report the same learning sequence: they spent months refining strategy logic, then lost significant equity in a single 24-hour period due to a VPS reboot during a volatile session, a missed network reconnection, or a terminal that silently froze without triggering any alerts. The strategy was fine. The infrastructure was the weak link.
The hard truth is that operational resilience delivers a higher return on your time investment than additional strategy optimization beyond a certain point. A strategy with a Sharpe ratio of 1.4 on reliable infrastructure will almost always outperform a strategy with a theoretical Sharpe of 1.9 running on a fragile setup. The first number compounds. The second one eventually blows up.
We’ve seen traders treat monitoring as a support function, something you configure once and check occasionally. At scale, monitoring and isolation are part of the trading system itself. Alert systems that fire immediately on terminal disconnection, equity drawdown thresholds, or execution gaps aren’t conveniences. They’re the mechanism that keeps capital intact when something unexpected happens, which it will.
Pro Tip: Build your operational infrastructure before you need it. The right time to configure your kill switches, alerting, and VPS redundancy is during a quiet period, not after a major loss event. Treat it like position sizing: non-negotiable, not optional.
The workflow for automation that survives contact with real markets is built on stability first and performance optimization second. The traders who internalize that order of priority are the ones still running accounts two years later.
Ready to automate and scale smarter?
Scaling your EA-based trading system is a serious undertaking that rewards preparation and punishes shortcuts. FxShop24 provides the tools, software, and resources to help you build that operation on a solid foundation.
Whether you’re looking for system guides for automation or need access to essential MT4/MT5 tools that are tested, prop-firm-ready, and built for real-world performance, the FxShop24 marketplace has you covered. Every EA available comes with lifetime updates, unlimited licenses, and support to help you scale with confidence rather than guesswork. Browse the full catalog and find the systems that match your trading goals.
Frequently asked questions
What are the main risks when scaling automated trading on MT4/MT5?
Capacity overload, VPS and network instability, and strategy overfitting are the most common risks, frequently leading to performance degradation or breached risk limits. Scaling to many terminals demands proper CPU/RAM allocation, and infrastructure reliability can become the primary constraint before strategy quality ever becomes the issue.
How can I prevent overfitting in my automated trading strategies?
Use walk-forward analysis and validate parameters with out-of-sample data that was never used during optimization. MT5 optimization should target stable parameter zones, not the single highest-performing historical result.
Do I need a separate VPS for each expert advisor?
Not necessarily, but each MT4/MT5 terminal needs its own allocated CPU and RAM, and isolation between terminals is strongly recommended. Each MT5 terminal runs its own instance, and resource conflicts between EAs sharing a terminal can cause unpredictable execution failures.
What automated risk limits are best for scaling?
Max daily loss thresholds and automated kill switches that close all positions and halt trading when drawdown limits are breached are the most critical tools. Automated risk limits are the mechanism that allows scaling without introducing discretionary and emotionally compromised decision-making.
How can I ensure my backtest results match live trading?
Benchmark execution live from day one and track slippage, fill ratios, and latency at full infrastructure scale. Realistic execution assumptions about fills and timing can dramatically change measured performance compared to what idealized backtests project.


